
How I automated quality assurance of pizzas in three weeks
I built my first edge computer vision system. I share what I built and how you can save time creating similar tools.

Welcome to 7 new subscribers since my last email 👋🏼

In the last three weeks, I built a prototype that runs in kitchens and identifies quality defects in pizza preparation. I expected the project to take two weeks, extended it to three, and now think it could be cut down to one week for similar future projects.
I always loved the idea of building a hardware device that runs neither on my laptop nor the cloud. But I never got to it. The unknown was too big.
This project has significantly lowered my hesitation towards hardware development. Now, the idea of building a small robot doesn't feel intimidating anymore. I want to share what the development of such a project looks like, how I built it, and hopefully reduce your barrier to building anything similar.

63 ghost kitchens
My client sells pizza through food delivery services but doesn’t manage their own kitchens. They collaborate with partner restaurants who prepare the pizza, all using the same recipe and ingredients. The partners earn additional revenue and my client has a lean business model. Everyone is happy.
But maintaining consistent quality is challenging when pizzas are made “part-time”. Rudy, the founder, had an idea: What if you had complete vision of all pizzas leaving their partner stores or could even detect defects before the order leaves the store?
Together we defined a minimal viable prototype. The goals were:
Identify any three of their 23 pizza types. I could choose.
Identify and count the ingredients on the pizza.
Operate fully autonomously in a store. No demo on a laptop.
What I built

Hotdog or no hotdog on the edge
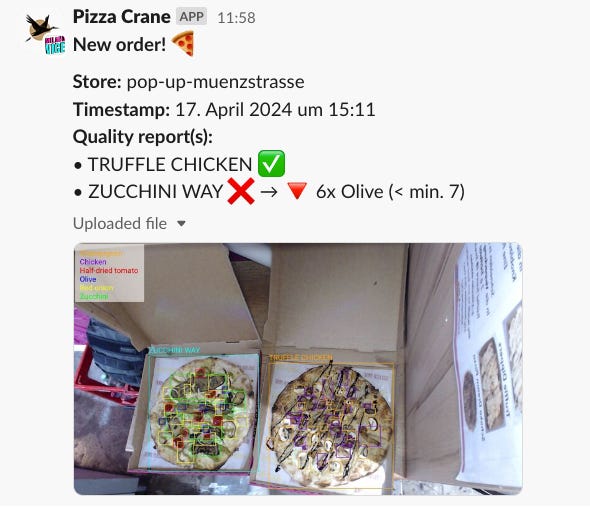
First, a camera connected to a small computer in the store detects whether it sees a pizza or not using a YOLO v8 model. Images of pizzas are uploaded to an AWS S3 bucket, while irrelevant images are not stored, minimizing wifi requirements and costs.
I also thought about streaming all images to the cloud and running the ML there. Storing all pictures at 5 fps would cost €46 per store per month. That’s ~€2900 for all stores. It only makes sense to keep the images with pizza and hence delete those without pizza. But I don’t like the idea of involving deletion logic in the code. There are of course safeguards you could add and my opinion on this matter might change in the future. For now, we kept the focus on iterating fast.
Most of the ML still runs on the cloud
Uploaded images trigger an AWS Lambda function that does the following:
Call 1st AI model: which pizza is it?
Call 2nd AI model: which toppings are on the pizza?
Count ingredients and compare them to the recipe. Identify any shortcomings.
Store the data in a NoSQL database.
Send a message to a Slack channel.
There was no reason to run this on the edge device. Keeping this code in the cloud makes it easier to maintain and easier to update the ML models.
Design choices, failures, and learnings
1 - I would not choose the Jetson Nano again.
The Nano is part of a series of hardware devices by Nvidia for edge machine learning. It’s like a Raspberry Pi but with a much stronger GPU. This benchmark, for example, shows the Nano to be 3x faster than the RPI 4. The RPI 5 came out last year and narrows the gap even more, although the Nano remains faster.
Still, after three weeks I see three reasons to choose a Raspberry Pi over the Nano: The RPI 5 costs 87€, the Nano 205€. The RPI has a faster CPU which makes it faster to run everything that is not an ML model. A wifi receiver is already built-in for the RPI while I had to buy an external one for the Nano at ~20€.
If blazing inference speed is crucial then get a Coral TPU. The Coral is basically a GPU equivalent on a USB stick that you can plug into an RPI to get 6x (!) the inference speed of the Jetson Nano. The only caveat is that your model needs to be compiled in TensorFlow Lite. This still allows you to build and train models in PyTorch, although some layers may not be compatible.



The main issue is that the Nano has reached the end of its lifecycle. It's limited to supporting Ubuntu 18.04, which comes with Python 3.6 pre-installed. Attempting to install versions beyond Python 3.8 leads to compatibility issues. Nvidia uses its own version of Ubuntu, resulting in even more complicated debugging. For instance, installing PyTorch via pip isn't straightforward; an "official" workaround is necessary. This was my biggest time sink, costing me 2-3 days to understand and resolve. I had to reflash the SD card three times and reconfigure everything due to uncertainties about error origins, potentially stemming from recently installed dependencies.
The follow-on to the Jetson Nano is the Jetson Orin Nano. It packs 40x the compute power of the Nano, but at 720€ also costs nearly 4x. This makes it too expensive for tinkering and smaller-scale use cases. But you can build cool things with the Jetson series, especially the bigger ones. I liked this Jedi Training Drone.
2 - Roboflow is very useful for training computer vision models
I trained custom models for pizza recognition using Roboflow, a platform for building image classification, detection and segmentation models. I just uploaded images and videos of the pizzas, labelled them online and trained my models with a few configuration options. You can also easily do this in Python (Ultralytics has many good Yolo guides), but Roboflow sped it up, particularly the labelling. Nevertheless, labelling took a lot of time though, maybe 1.5 days in total. You can outsource this but doing it yourself initially is worth the investment because you understand the edge cases your model has to deal with and think more about the training data you collect.
Doing all this labelling rekindled my Sierra Leonean labelling idea. Revisiting it, albeit not as a business, may be worthwhile for a client project with more data.
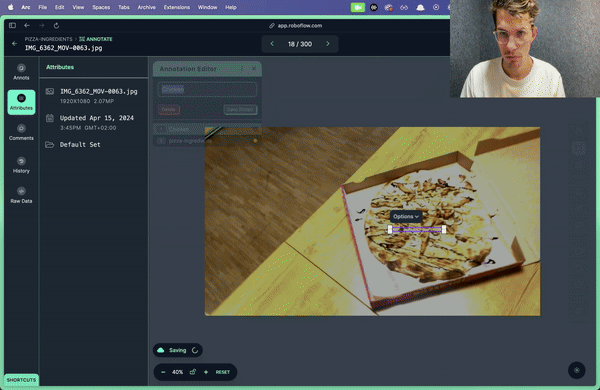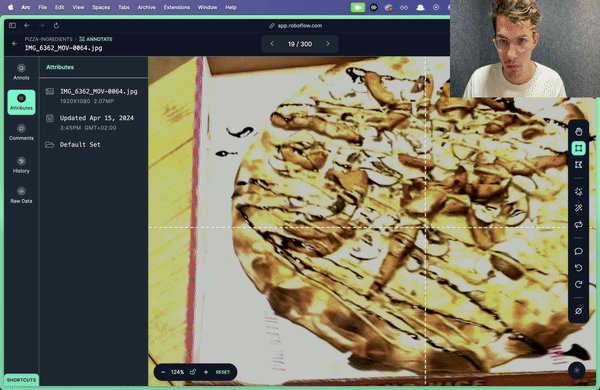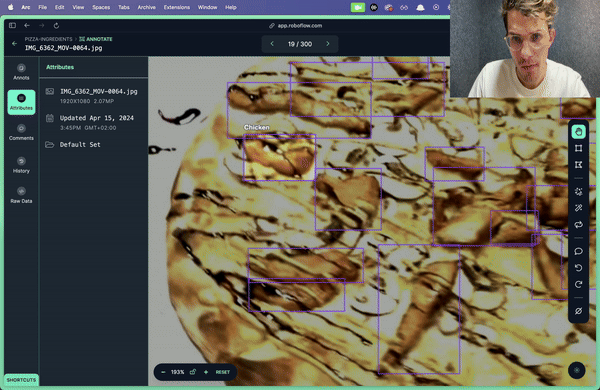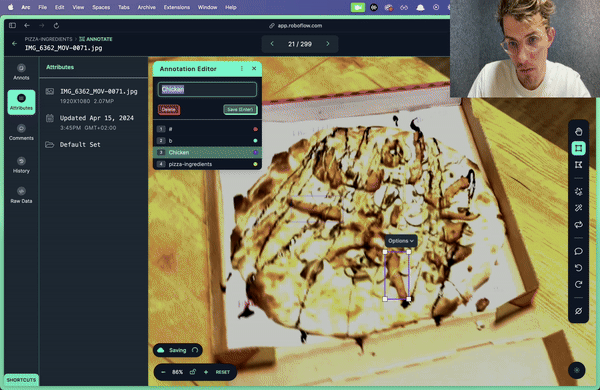
3 - First time with Lambda functions: I’m a fan.
We receive bursts of images during lunch and dinner but take little to no images during the rest of the day. For our case, Lambda functions (serverless) are ideal.
Python Lambda functions are easy to set up but can become a pain once you require multiple Python dependencies. For example, it’s not straightforward to install Numpy and Pandas (WTF?). I initially built a Lambda layer and had to write a script to download and install pandas from a .whl file every time I wanted to update it. That was tedious and when I needed OpenCV I exceeded the maximum size and ended up moving to docker-based lambda functions. That’s the only way I’d do it moving forward because it makes development and local testing so much easier.
Technically it’s more work because you have to build the docker image again every time, push it to an image repo and then update the lambda. But I invested in setting up GitHub actions to automate this and it did save me a LOT of time. It did, however, also take time to set up. I created this GitHub gist for anyone planning to do the same, hopefully saving you the headache I had.
I love GitHub Actions and automating as much as possible with CI/CD. I started auto-deploying to render.com for Granny Mail and have been using them since.
4 - It’s more fun working in teams
The alarm at the office turns itself on at 11 PM every day. On Thursday, the final day of coding, I was wrapping up final changes to the Lambda function and lost track of time. Suddenly, I heard the warning sound of the alarm, which signals that you have 60 seconds to leave and lock the office before it goes off. I made the mistake of ignoring that earlier that week. I grabbed my backpack and ran outside with the laptop in the other hand. But I needed wifi to commit. And so I spent another 15 minutes debugging on the curb at 3° Celsius.
Coding late and fixing the stupid bugs that are keeping you up is like getting stuck in a lift: It’s more fun when it happens with another person. If I were doing this with a partner, finishing the project with freezing fingers on the sidewalk might be one of those stories you'd reminisce about years later—ideally with the business running even better. On my own, it’s rather something I’ll have forgotten a few months later.
On my way home I decided to make finding another person to work with a higher-ranking priority. It's more fun and whoever has the most fun ends up building better.
If you know cool people who can code, intrinsically enjoy building things, and aren’t locked into a PhD or similar long-term commitment, please let me know.
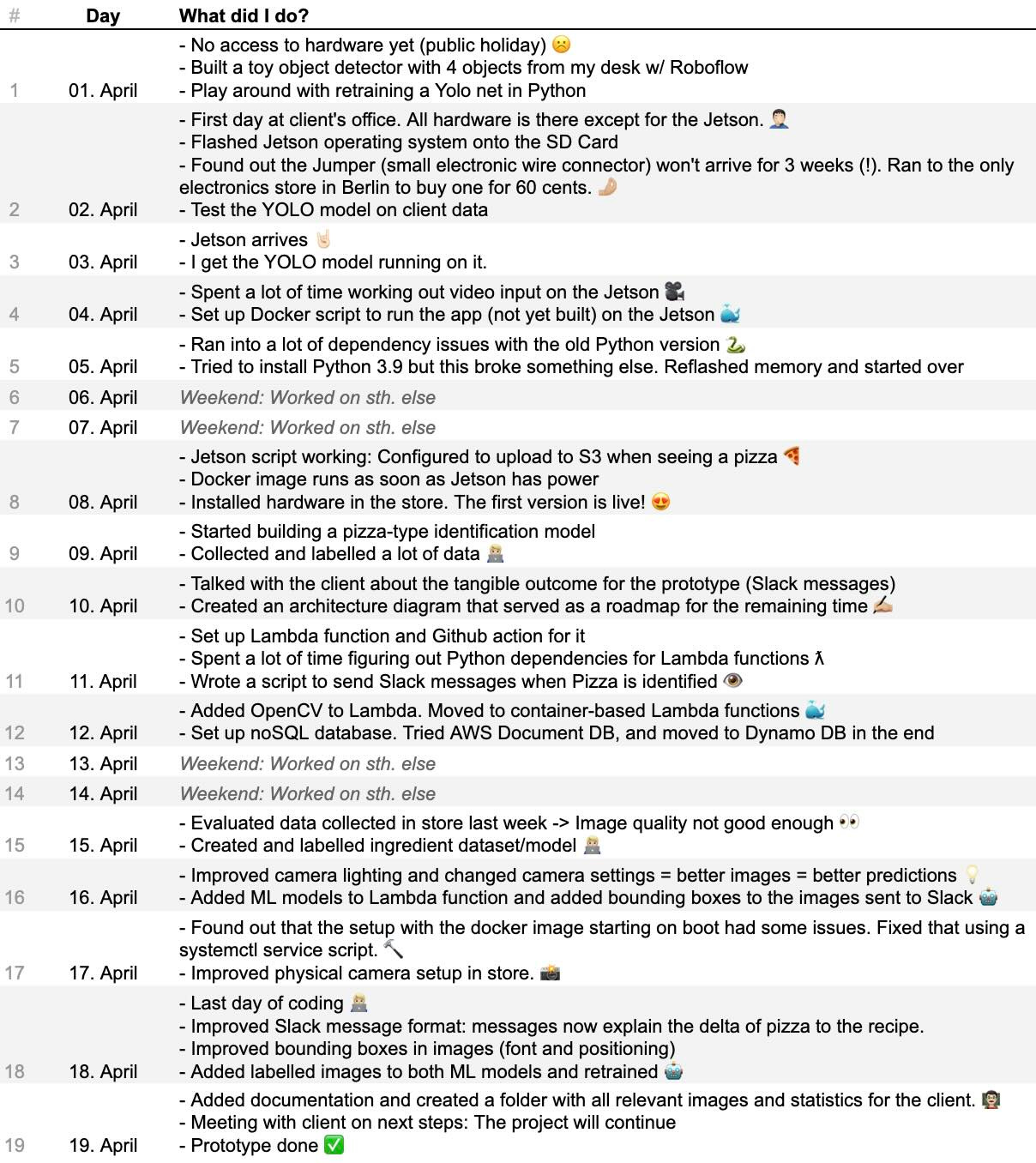
A timeline of the project day by day.
Why does software development take so long? What went well for this project? Where did I lose time?
I documented everything I did each day to answer these questions.
Personal notes for next time
(1) Limit coding to no more than 10 hours per day. Just go to bed and take a fresh look at things the next day.
On two occasions I stayed up until 5 AM fixing a bug. I solved it the first time. The second time I gave up at 5 AM and the next day I just took a step back and used a different approach. At some point I just find myself brute-forcing things I find on Stack Overflow without thinking about the underlying issue.
(2) Avoid working with legacy hardware and operating systems.
Navigate your own bugs, not those introduced by running new software on outdated systems.
(3) Have a vision for the final result.
I knew what to build but without the final output being clear (eventually the Slack messages) it was hard to work backwards from something. Defining this with the client and sketching the architecture diagram was important to speed up development.
(4) Keep documenting your day-to-day work more.
I’m the kind of person who doesn’t know what he had for dinner two days ago. I’m happy that I wrote this down. Reading this now I’m proud of what I did and reminds me of how much I've learned in just three weeks. It’s motivating to do more.
(5) Use CI/CD as much as possible.
(6) Keep feedback loops as short as possible.
I lost a lot of time setting up GitHub actions for Lambda functions because it took three minutes to get feedback on whether a change fixed the issue (I just kept pushing). I’m still not sure how to iterate on CI/CD faster though.
My top reads of the week
There are too many AI models: Improvements are incremental and there’s no point in staying up to speed.
This article resonated with me. I subscribed to six AI newsletters last year and unsubscribed one by one. AINews is an exception. I subscribed after Andrej Karpathy’s recommendation. It’s VERY long but covers everything. You need to filter.
Microsoft’s VASA-1 model can turn any image + text into a virtually flawless video of the person speaking.
Neuralink has its first user with a working brain implant
Paralyzed below his shoulders, Noland can now control a computer’s cursor just by using his mind. He can now play chess and Civilization on his laptop.
Competition for Nvidia? Groq is setting a new standard for LLM inference
GPT 3.5 runs at a maximum of 109 tokens/second for example. Groq can serve Llama3 at 800 tokens/s. This video highlights the difference.
Of the top 50 consumer-facing AI apps (by web traffic), 40% are new compared with September 2023. Interesting: ChatGPT gets 2 billion visits a month, roughly 5x Gemini. Character AI is #3: I’m amazed that companionship apps are the most successful new category created by LLMs. This is a cool chart of current revenue multiples.
I got caught riding without a ticket by the BVG in Berlin. I deserved it but I think it’s economically more rational to pay the fine than buy the ticket. I’d like to build an app to track my rides and prove that point. I looked into it and expo.dev looks like a very cool tool to develop apps that run cross-platform and on the web.
Screen.studio creates beautiful screen recordings.
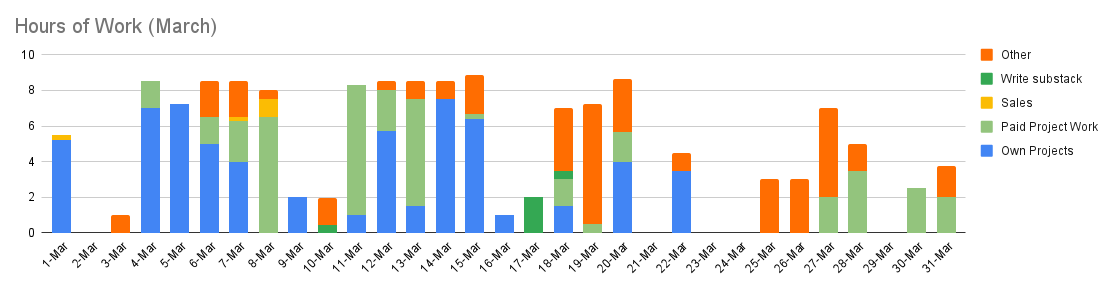
My time allocation in March
I mentioned my time tracker earlier this year and how I use it for accountability. Sharing it motivated me to stay persistent and I want to continue. Here’s last month.
Interesting write up here boss,I live building new things,but still learning to code.
Very cool project but more importantly this post is extremely motivational. Thanks a lot!