
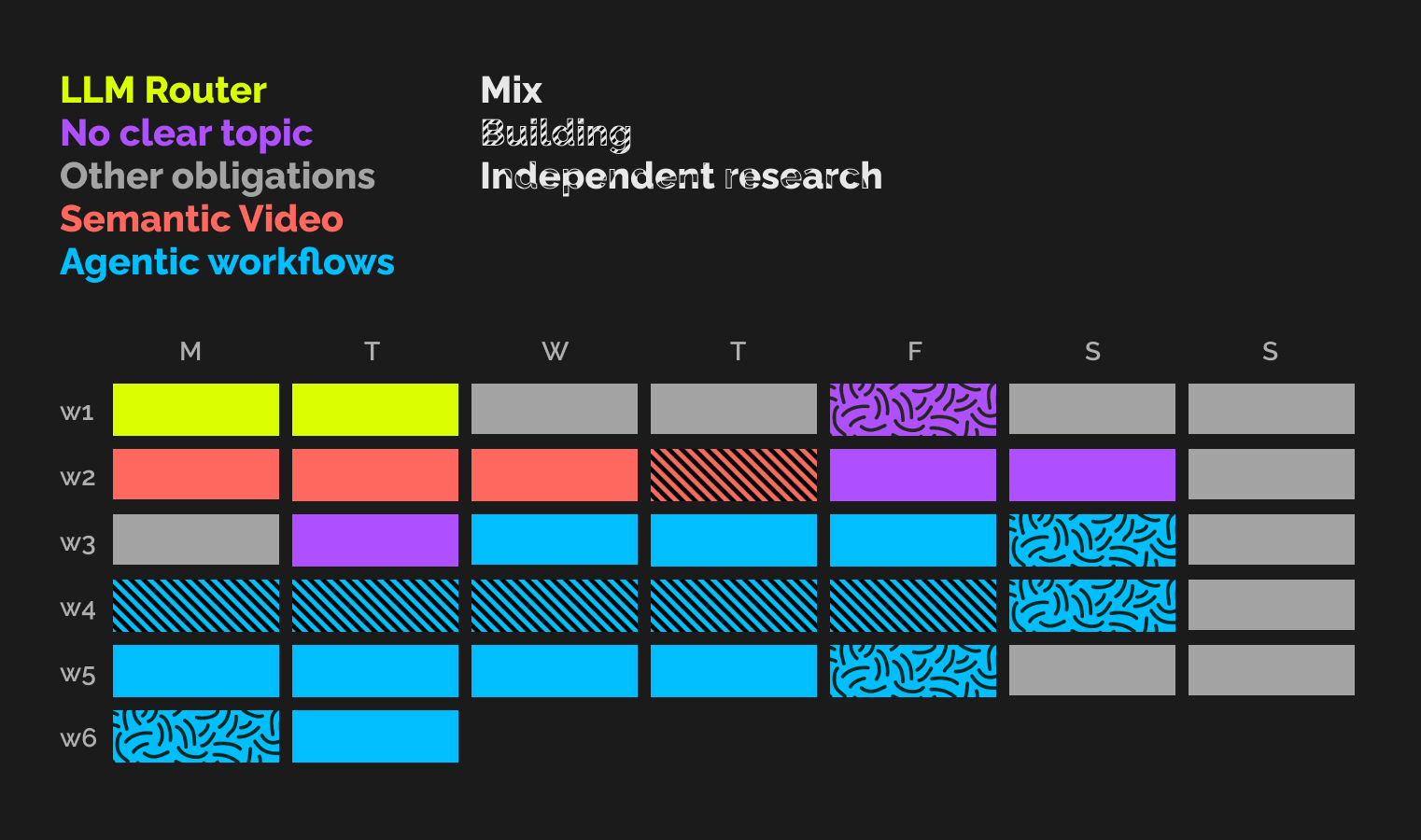
Moving from freelancing to ideating in July
What we've worked on in the last 5 weeks and how this changes how I think about ideation.

Welcome to the 11 new subscribers since my last email 👋🏼. This newsletter has crossed the 💯 subscriber mark this week.
Charlotte and I met during the ETH Statistics master’s. She briefly worked at Meta and spent the last year building a start-up focussed on RAG. Earlier this year, we began exchanging thoughts on coding problems and system architecture. By June, our discussions had escalated to exchanging DINA4-length messages.

End of June, we were both ready for something new and were lured by the idea of working with a technical person who also has a business interest.
Initially, we decided to work together for 1-2 days per week for a month. The first two days were promising—interpersonally, things clicked. So, we switched gears to work 100% for the month, albeit with some existing work obligations. On August 9th, we'll reassess and decide how to continue.
This month has been intense in a positive way. We’ve gone through a few cycles of being hyped, then disillusioned, and then getting our heads up again. We’ve evaluated ideas with pen and paper and also built a prototype. I’ve learnt (and am still learning) a lot about separating excitement from conviction and which signals to care about. As for the business idea, we’re still at -1.
In May/June, I couldn't share many details about my freelancing due to NDA restrictions. Now, there are no limits on what I can share about my work. There is no clear-cut story yet—just ideas and an emotional rollercoaster. Our plans might as well change in a week. But this is exactly the adventure I’m up for, and sharing my experiences is why I started this email list.
The first cosine wave of excitement was the shortest one and started on day 1.
The open-source LLM router.
Working with LLMs, one thing we’ve seen is that there's a significant trade-off: You need to choose between using the best and most expensive model (like Claude or GTP4o) or the cheaper one with lower quality on hard tasks (like Llama 7B).
What if you could get better quality AND a lower price at the same time? Not every query needs the best LLM. Some queries are hard, others are childishly easy. If you can identify the complexity of the query before making the API call you can send (i.e. route) the difficult queries to the big and expensive model and the easy queries to the smaller and cheap model.
And actually, you don’t need to stop there. There isn’t a single “best” model for everything. Claude is great at coding, Mistral 2 at math, GPT4o at reasoning and so on. You can probably get better results through accurate routing than by just sending it to the best model overall. Competitors in this space exist, but we hypothesised that taking an open-source approach would be more developer-friendly and long-term viable.
But on day 2 things took a turn. LMSYS, a highly respected open-source organisation, announced their release of an open-source router trained on data from the chatbot arena (the de facto LLM comparison leaderboard that they run). Their results blew existing commercial competitors out of the water.
This was a downer. We were hyped about the idea. But given LMSYS's reputation and their results, this idea would be a long journey with high uncertainty of whether we could beat their results, and with no clear differentiating angle.
Also, there was this other idea in the back of my mind that had originated from a project I've worked on with friends, promoting field hockey in Sierra Leone.
Semantic search for videos
I often edit videos for our project and a huge pain I have is finding the right footage for video edits. Creating this three-minute video took me half an hour of recording and 11 hours of editing. I spent 8 of those hours only searching my hard drive for clips! The crazy thing is I already know which shot I’m looking for. I just don’t know when I shot it and where it is on my hard drive.

Searching through videos takes particularly long. Flipping through images takes less than a second, but with videos, you need to watch a few seconds of each clip. This is not only a problem that I have. Professional editors we talked to confirmed that this consumes multiple days of a two-week project or 30-60% of their time per project.
But with hours spent searching through my own hard drive, I also had had enough time to dream about what a solution would look like.
What if you could search your hard drive not my name or folder by the file, but what’s in the video? For example “drone shot with car, forest background” or “children playing hockey on a dust field”.
Yet this idea also didn’t find a happy ending. We quickly learnt of a smaller competitor and saw their existence as a confirmation of the problem. But when we started sizing the editing software market we noticed that it might be quite small.
Hmm, not good. When we then found another more feature-rich product (thank you Max C. for sending) with significant funding we decided to pull the plug on this idea too. Our ideas for the product were mostly subsumed in competitor 2’s product. And we weren’t interested in copying features for a few months.

Ok, another emotional cosine curve. But this curve had a smaller amplitude. We were growing some thicker skin. Also, I’m now looking forward to becoming a user and saving time on my next edit.
After killing both ideas we wanted to ensure that our reasoning for moving on was sound and we weren’t being purely emotional. Also, a summary by a friend (Max) had helped us and we wanted to pay it forward to anyone else thinking about the two problems. We wrote a post-mortem summarising the idea, our learnings and our reasoning for moving on. You can find them here and here respectively.
Time to rethink our approach
Both ideas existed in our heads before coming together. Now, Charlotte and I needed to move from evaluating a pre-existing hypothesis to actively searching for ideas.
Two things were clear to us. Whatever we work on should…
Sufficiently excite us to work on it for 5+ years.
Primarily be a technical challenge.
It’s easy to look up to other start-ups for their success. But you only have one life. Would you really want to have built that product for 5+ years? It gets even harder assuming that the company won’t be a success which is the median outcome after all. We asked ourselves this question and what companies we would have loved to have founded. I asked myself this question for every company I came across on Twitter and TechCrunch the next week. There were many fast “nos” and very few clear “yeses”.
We noticed that flip-flopping between ideas and switching between all dimensions of technology, industry and end-user means losing all the knowledge you built working on your previous idea. Adding a constraint makes things easier.
We decided on agentic workflows.
Agentic workflows sometimes also called AI agents just mean using an LLM to reason about which actions should be taken to accomplish a goal and execute code on the LLM’s behalf. Imagine that instead of only writing a sales email for you, GPT could also send that email for you, handle the conversation autonomously, add a corresponding entry in your CRM, and schedule the call for you. Now imagine you could tell it to do all of this on its own and just line up calls in your calendar. This is just one example for sales. The key idea is that an LLM can take actions and can do so autonomously.
AI agents are exciting because they in theory allow you to automate to such an extent that you could completely replace humans, but at the same time, the failure rate is still too high. The main critique is that the technology isn’t ready yet.
Sounds like a cool problem to work on.
In week 3 we built an agent observability tool
This idea originated from Charlotte’s previous work on RAG where debugging was a huge pain. The idea: Visualise the flow of data through the chain of LLM and RAG calls.
We aimed for a working prototype in two weeks but finished it on day 5. This was an incredible feeling and a moment where we both without saying were thinking the same thing: Together, we might have some crazy iteration speed.
For my fellow techies: we used Typescript, NextJS, Supabase, and Render for the web app visualising the results and built a simple Python SDK to create the logs.

However, we noticed that logging in Python was more cumbersome than anticipated without integrating with a framework like Langchain. We adjusted the course and decided to focus on getting our hands dirty building an agent for week 4. This helped us notice knowledge gaps and helped us develop a better understanding of what agent applications could feel like and how to build them. I implemented a simple email dispatching tool (watch a demo here). Running into a few problems doing so shaped my understanding of why there is a market for products like LLM memory.
We’re less bullish on the observability tool now and at an open point where we haven’t decided on what to focus on next.
Deciding to focus on agents was important. But my growing impression is that this is not enough.
The best approach to building: ‘Aim & Fire’ or ‘Fire and Aim’?
‘Aim and fire’ is the classical lean start-up advice: Talk to people, ask them about their problems, find user profiles, and only build once you’ve sold a mockup. It’s the “A/B-test your way to success” approach.
But maybe it makes more sense to just build what you think is interesting and use whatever you build to engage users. Whatever we start building will most likely not be “it”. But my current belief is that getting your hands dirty with new tech and writing code will accelerate our understanding of what’s possible, where the frontier is, and how users want to interact with - in our case for now - agentic tools.
Yes, building and selling takes more time than just selling. Losing time is the obvious risk of “just build”, but our prototype in week 3 motivates me to think that we can actually move faster this way and that this will rather lead us to a unique insight.
So, the path ahead is not clear yet, but I’m very excited to code more in the next few weeks.
Thanks for reading! If you know anyone else building in the agent space I’d love to connect with them.
What I’m reading - News & Papers
1 - Meta and Mistral launch two open-source models
Meta released its 405 billion parameter model and newer versions of its 70bn and 7bn parameter models. The biggest one is on par with Claude and GPT4.
On the same day, Mistral launched its Mistral Large 2 model which has 123bn parameters and beats Llama 70bn. It’s exceptionally good at math and coding.
While Meta has shared its models with open weights and a free-to-copy license Mistral’s model has a research license and is restrictive for commercial use.
2 - How to get start-up ideas
I reread PG’s essay this month and highly recommend it to anyone who eventually wants to found a start-up, but is not quite sure how they’ll find the idea. The key point I’ve been coming back to again and again is: “Live in the future and build what’s missing”.
3 - AI Tinkerers event: A very cool multi-city event for people who love coding
AI Tinkerers is a locally organised event in which hobby developers demo what they built in six minutes. I was at the Berlin event and loved it. There are events in dozens of cities, albeit not so often.
4 - Getting from -1 to 0
This is obviously a question that’s been sitting in my frontal lobe for 4 weeks now. I enjoyed Andrew Ng’s perspective on this as well as Southpark Commons’ article. My takeaway: Fire and aim.
But I am currently biased and should consider whether I’m ignoring the hundreds of other sources that will tell you to aim and fire. Why is so much start-up advice contradicting other start-up advice?
My top 5 Papers of the month
Ranked in descending order. All of these were incredibly interesting and expanded my beliefs about what LLMs might be doing in the next few years.
1 - MemGPT
Packer et al. (Oct. 2023) - Arxiv & Company page
Big idea: What if you use left-over space in an LLM’s context window to store “memories” of past interactions? You’d think that you’d try and implement memory programmatically, but the authors just use the prompts to let the LLM manage its memory autonomously by giving it access to database functions.
This paper gave me a completely new perspective on Andrej Karpathy’s “LLM OS” tweet. I highly recommend watching this video after reading the paper (or instead if you’re not going to read the paper anyway I guess).
2 - Voyager
Wang et al. (May 2023) - Arxiv & Project page
Big idea: AI Agent learns to play Minecraft by writing and debugging its own code that it can store in a database and later retrieve via RAG.
This idea of an agent learning its own toolbox got me very excited.
3 - STORM
Shao et al. (Feb. 2024) - Arxiv, Github and Demo
Big idea: Can you write Wikipedia articles from scratch by giving an LLM access to the web and using complex prompting patterns?
I found this very interesting because it gave me an idea of what agentic workflows can look like and how “just chaining prompts together” is going to get you that far. They also use a few techniques and tools that I didn’t know of.
4 - DSPy
Khattab et al. (Oct. 2023 & Jun. 2024) - Arxiv & Github
Big idea: What if we could use back-propagation to improve LLM prompts and improve them programmatically instead of just trying things out?
Yes, I’d love to not think about writing good prompts.
5 - Mixture of Agents
Wang et al. (Jun. 2024) - Arxiv & Github
Big idea: What if you 1) ask multiple LLMs to answer and 2) then another group of LLMs to synthesise the previous group of responses? The authors show that a group of cheaper LLMs actually generates a higher quality output than if you ask for a better LLM.
This is meaningful because it means that you can actually beat e.g. GPT4 by using multiple open-source models together. Using Groq you can also beat GPT4 on latency.